45 class labels in data mining
PDF Data Mining Classification: Basic Concepts and Techniques lGeneral Procedure: - If Dtcontains records that belong the same class yt, then t is a leaf node labeled as yt - If Dtcontains records that belong to more than one class, use an attribute test to split the data into smaller subsets. Recursively apply the procedure to each subset. Dt ID Home Owner Marital Status Annual Income Defaulted Borrower 13 Algorithms Used in Data Mining - DataFlair That is to measure the model trained performance and accuracy. So classification is the process to assign class label from a data set whose class label is unknown. e. ID3 Algorithm. This Data Mining Algorithms starts with the original set as the root hub. On every cycle, it emphasizes through every unused attribute of the set and figures.
Data mining — Specifying the class label field This section describes how you can specify fields with a class label and provides an example. Class labels can include up to 256 characters. Use DM_setClasTarget to specify the class label field (target field) for a DM_ClasSettings value. The mining data type of this field must be categorical. The specification of this field is mandatory.
Class labels in data mining
Assigning class labels to k-means clusters - Cross Validated Cross Validated is a question and answer site for people interested in statistics, machine learning, data analysis, data mining, and data visualization. It only takes a minute to sign up. Sign up to join this community. ... (assigning meaningful class labels to each cluster). I am not talking about validation of the clusters found. PDF Data MiningJHan Chapter8 Classification - Cleveland State University measurements, etc.) are accompanied by labels indicating the class of the observations New data is classified based on the training set Unsupervised learning (clustering) The class labels of training data is unknown Given a set of measurements, observations, etc. with the aim of establishing the existence of classes or clusters in the data › distance-based-outlierDistance-Based Outlier Detection in Data Mining Mar 04, 2022 · Outlier detection methods can be categorized according to whether the sample of data for analysis is given with expert-provided labels that can be used to build an outlier detection model. In this case, the detection methods are supervised, semi-supervised, or unsupervised.
Class labels in data mining. machine learning - Class labels in data partitions - Cross Validated Suppose that one partitions the data to training/validation/test sets for further application of some classification algorithm, and it happens that training set doesn't contain all class labels that were present in the complete dataset, i.e. if say some records with label "x" appear only in validation set and not in the training. What is the Difference Between Labeled and Unlabeled Data? Unlabeled data is, in the sense indicated above, the only pure data that exists. If we switch on a sensor, or if we open our eyes, and know nothing of the environment or the way in which the world operates, we then collect unlabeled data. The number or the vector or the matrix are all examples of unlabeled data. Data Mining - Classification & Prediction - Tutorials Point In this step the classification algorithms build the classifier. The classifier is built from the training set made up of database tuples and their associated class labels. Each tuple that constitutes the training set is referred to as a category or class. These tuples can also be referred to as sample, object or data points. Difference between classification and clustering in data mining? 1. The Key Differences Between Classification and Clustering are: Classification is the process of classifying the data with the help of class labels. On the other hand, Clustering is similar to classification but there are no predefined class labels. Classification is geared with supervised learning.
› data-reduction-in-data-miningData Reduction in Data Mining - GeeksforGeeks Dec 15, 2021 · Prerequisite – Data Mining The method of data reduction may achieve a condensed description of the original data which is much smaller in quantity but keeps the quality of the original data. Methods of data reduction: These are explained as following below. 1. Data Cube Aggregation: This technique is used to aggregate data in a simpler form. Decision Tree Algorithm Examples in Data Mining The algorithm starts with a training dataset with class labels that are portioned into smaller subsets as the tree is being constructed. #1) Initially, there are three parameters i.e. attribute list, attribute selection method and data partition. The attribute list describes the attributes of the training set tuples. Basic Concept of Classification (Data Mining) - GeeksforGeeks Classification is the problem of identifying to which of a set of categories (subpopulations), a new observation belongs to, on the basis of a training set of data containing observations and whose categories membership is known. Example: Before starting any project, we need to check its feasibility. Data Mining Techniques - GeeksforGeeks In general, the class labels do not exist in the training data simply because they are not known to begin with. Clustering can be used to generate these labels. The objects are clustered based on the principle of maximizing the intra-class similarity and minimizing the interclass similarity.
Data Mining - (Class|Category|Label) Target - Datacadamia A class is the category for a classifier which is given by the target. The number of class to be predicted define the classification problem . A class is also known as a label. Spark Labeled Point Various Methods In Classification - Data Mining 365 Classification is the data analysis method that can be used to extract models describing important data classes or to predict future data trends and patterns. (Read also -> Data Mining Primitive Tasks) Classification is a data mining technique that predicts categorical class labels while prediction models continuous-valued functions. In data mining what is a class label..? please give an example Basically a class label (in classification) can be compared to a response variable (in regression): a value we want to predict in terms of other (independent) variables. Difference is that a class labels is usually a discrete/Categorcial variable (eg-Yes-No, 0-1, etc.), whereas a response variable is normally a continuous/real-number variable. Data mining — Class label field - IBM Class label field. To identify customers who have allowed their insurance to lapse, you can specify the data fields that are shown in the following table: Table 1. Selected input fields for the Classification mining function. Input fields. Class label field. Town districts. Risk class.
Decision Tree in Machine Learning | by Prince Yadav | Towards Data Science
Multi-Label Classification with Deep Learning We can create a synthetic multi-label classification dataset using the make_multilabel_classification () function in the scikit-learn library. Our dataset will have 1,000 samples with 10 input features. The dataset will have three class label outputs for each sample and each class will have one or two values (0 or 1, e.g. present or not present).

› publication › 49616224_Data(PDF) Data mining techniques and applications - ResearchGate Dec 01, 2010 · Data mining is a process which finds useful patterns from large amount of data. The paper discusses few of the data mining techniques, algorithms and some of the organizations which have adapted ...

shareengineer: DATA WAREHOUSING AND MINIG ENGINEERING LECTURE NOTES--Mining Various Kinds of ...
› regression-in-data-miningRegression in data mining - Javatpoint Regression in data mining. Regression refers to a data mining technique that is used to predict the numeric values in a given data set. For example, regression might be used to predict the product or service cost or other variables. It is also used in various industries for business and marketing behavior, trend analysis, and financial forecast.

Data Mining - Tasks - Tutorials Point Data Mining - Tasks, Data mining deals with the kind of patterns that can be mined. On the basis of the kind of data to be mined, there are two categories of functions involved in D. ... Prediction − It is used to predict missing or unavailable numerical data values rather than class labels. Regression Analysis is generally used for prediction.

Classification on multi label dataset using rule mining technique
Classification and Predication in Data Mining - Javatpoint Classification is to identify the category or the class label of a new observation. First, a set of data is used as training data. The set of input data and the corresponding outputs are given to the algorithm. So, the training data set includes the input data and their associated class labels.
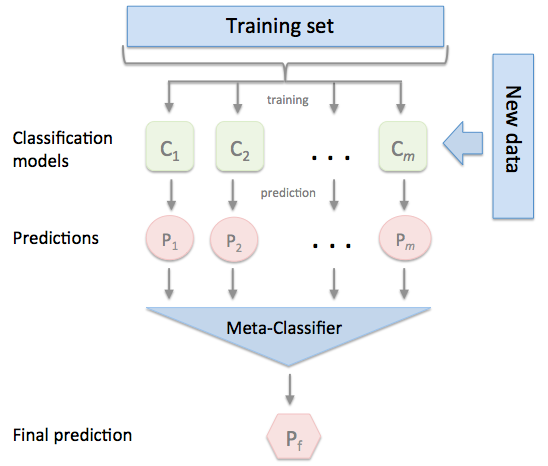
StackingClassifier - mlxtend
What is the difference between classes and labels in machine ... - Quora Class label is the discrete attribute having finite values (dependent variable) whose value you want to predict based on the values of other attributes (features). LABEL: 'Classification' is a type of problem whereas 'labeling' is a function trying to label an object and classify using the informati Continue Reading More answers below Pukar Acharya
Data Mining — Knowage documentation
Table 1 . Examples, class labels and attributes of datasets. Live sensor data is aligned with the recognized person name being class label to perform multi class classification. This research explains to perform optimization of person prediction using sensor...

The direct-read CAD data model—Help | ArcGIS Desktop
Classification & Prediction in Data Mining - Trenovision predicts categorical class labels (discrete or nominal). classifies data (constructs a model) based on the training set and the values (class labels) in a classifying attribute and uses it in classifying new data. Prediction models continuous-valued functions, i.e., predicts unknown or missing values. Supervised vs. Unsupervised Learning

Data Mining: Association Rules Basics
Classification in Data Mining - tutorialride.com Classification predicts the value of classifying attribute or class label. For example: Classification of credit approval on the basis of customer data. University gives class to the students based on marks. If x >= 65, then First class with distinction. If 60<= x<= 65, then First class. If 55<= x<=60, then Second class.
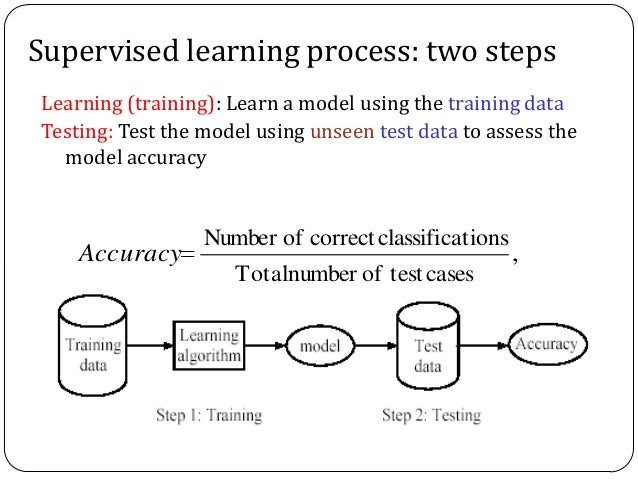
Presentation on supervised learning
Classification in Data Mining Explained: Types ... - upGrad blog Every leaf node in a decision tree holds a class label. You can split the data into different classes according to the decision tree. It would predict which classes a new data point would belong to according to the created decision tree. Its prediction boundaries are vertical and horizontal lines. 4. Random forest

Introduction to Labeled Data: What, Why, and How - Label Your Data This way, after the training process, the input of new unlabeled data will lead to predictable labels. You add labels to data and set a target, and the AI learns by example. The process of assigning the target labels is what we know as annotation Click to Tweet. To put it simply, this means that you add labels to data and set a target, and the ...

Classification on multi label dataset using rule mining technique
PDF Data Mining Classification: Alternative Techniques - A method for using class labels of K nearest neighbors to determine the class label of unknown record (e.g., by taking majority vote) Unknown record 2/10/2021 Introduction to Data Mining, 2 nd Edition 4 How to Determine the class label of a Test Sample? Take the majority vote of class labels among the k-nearest neighbors

Data Mining Concepts 15061
Data Mining Bayesian Classification - Javatpoint Data Mining Bayesian Classifiers In numerous applications, the connection between the attribute set and the class variable is non- deterministic. In other words, we can say the class label of a test record cant be assumed with certainty even though its attribute set is the same as some of the training examples.
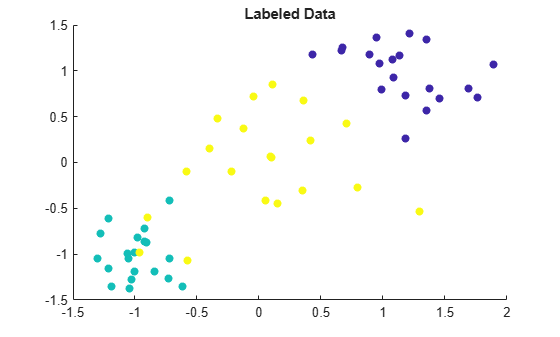
Label data using semi-supervised graph-based method - MATLAB fitsemigraph
› distance-based-outlierDistance-Based Outlier Detection in Data Mining Mar 04, 2022 · Outlier detection methods can be categorized according to whether the sample of data for analysis is given with expert-provided labels that can be used to build an outlier detection model. In this case, the detection methods are supervised, semi-supervised, or unsupervised.

특허 US20050071251 - Data mining of user activity data to identify related items in an electronic ...
PDF Data MiningJHan Chapter8 Classification - Cleveland State University measurements, etc.) are accompanied by labels indicating the class of the observations New data is classified based on the training set Unsupervised learning (clustering) The class labels of training data is unknown Given a set of measurements, observations, etc. with the aim of establishing the existence of classes or clusters in the data
Post a Comment for "45 class labels in data mining"